Snow Leopard upgrade notes
The latest cat from Apple was released August 28. Here are some notes and observations relevant to the https://divvun.no/ and http://giellatekno.uit.no/ projects.
General impression
Faster, especially Mail. All sorts of nice touches and improvements, some software incompatibilities, but no big hurdles. At least some, possibly many of the command line tools are updated to recent or the latest version, e.g. svn, bash, cvs, perl, etc.
Specific new features interesting to us
Automatic language detection
This is used to select spell checking language automatically. The quality of this detection is unknown, also the range of languages detected, as well as exactly how it works, and whether it is possible to add new languages.
After some initial testing, it seems that big languages are detected — English and German in my case — but not smaller ones, like Norwegian or Sámi. Others have had success with mixing English, Spanish, French, Italian and Greek.
It is possible to specify the spelling language manually, but then only one language pr doc in most Cocoa applications (explicit multilingual markup must be added specifically for each app, it is not supported by the Cocoa framework).
Direct support for hunspell files
The OS will recognise aff and dic files placed in Library/Spelling/, and based on reports on the net (“of the type used in OpenOffice”), it seems to be hunspell aff and dic files.
[images/spellingdir.png]
As soon as you place such files in that location, the language will be recognised in the Language and Text > Text system preference:
Adding North and Lule Saami spell checking in Snow Leopard \Picture: Adding North and Lule Saami spell checking in Snow Leopard.
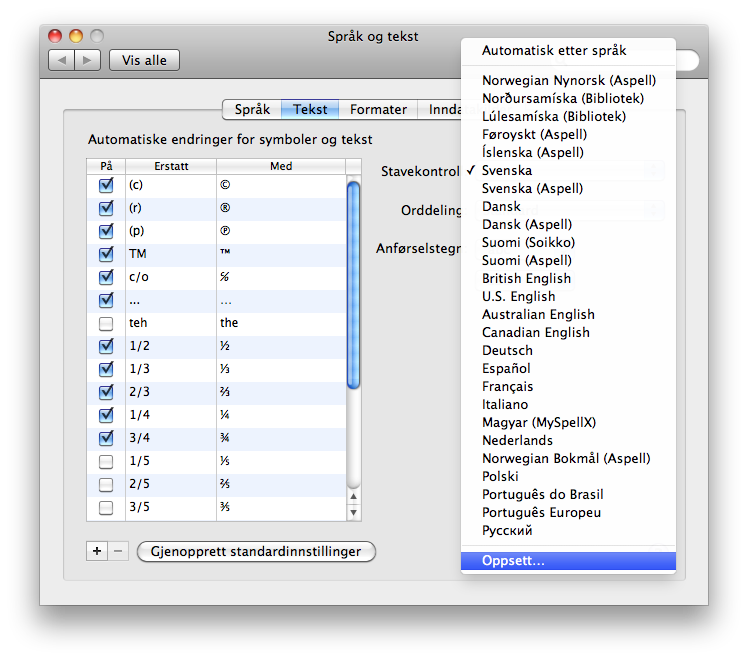{kind=link}
North and Lule Saami spelling languages turned on \Picture: North and Lule Saami spelling languages turned on.
{kind=link}
Turning on Saami spell checking in the system preferences makes the languages available in most Cocoa applications, as shown in the spelling dialog below:
Language list in spelling dialog
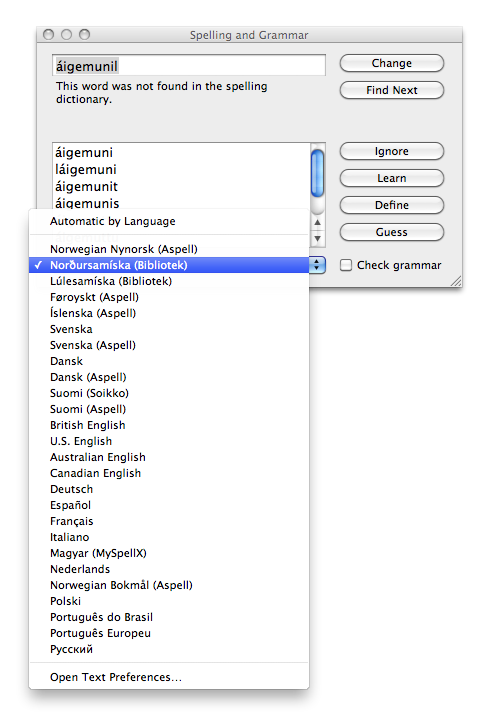{kind=link}
And it does actually work:
[images/sme-spelling-in-see.png]
We finally have system-wide spell checking in Sámi, without having to resort to third-party tools!
It still seems to be a bit fragile. Finder restarted once while I was playing with this, and due to the size of our hunspell dic+aff files, spelling was sometimes slow. But most of the time it seemed to work, and I had no nasty crashes.
Other System Speller improvements
Immediate speller language change
In previous versions of Mac OS X, you had to restart Cocoa applications if you changed the speller language. Now the new language takes effect immediately, which means it is actually possible to switch languages in e.g. iChat.
Keyboard shortcut both opens and closes speller dialog
Earlier, when opening the speller dialog using Cmd-: the dialog would be stuck, and you had to reach for the mouse to close it. Now you just press the keyboard shortcut again, and the dialog box disappears. (You need the dialog box to change speller language.)
Features still missing
Interface languages
Although quite a few more languages are available in the interface language preference list, there are still very few three-letter language codes there. This means that only North Saami is available, and there is no possibility to add other Saami languages, or any other missing language for that matter.
The few three-letter-coded languages found so far are (ISO 639 code in parenthesis):
- Cherokee (
chr) - Klingon (
tlh) - Neapolitan (
nal) - Sicilian (
scn) - Swiss German (
gsw)
An interesting collection indeed. At least it shows that three-letter ISO 639-codes aren’t foreign to Mac OS X. But it also shows a certain language priority in Cupertino…
System wide spell checking - only one language setting per application
Although the system-wide spell checking service is vastly improved, it still has one major drawback: when you change the spelling language for one document, the same language is applied to all documents.
As long as you can use the multilingual spelling with automatic language detection, that is fine, but as soon as you have to resort to manually specifying the language of the document, this system breaks down. Then all my open documents in the same application will be spell-checked as the same language. This is at least how it works in SubEthaEdit.
Software with available updates
The latest version available is tested and known to work fine on Snow Leopard, earlier versions are problematic:
- Version.app (graphical subversion client)
- SubEthaEdit
- iStat menus
- Cisco VPN client
- GROWL 1.2
- ICU - VISLCG3 requires the latest ICU package (possibly Xerox as well). Use MacPorts to install or upgrade, either using the command line
sudo ports upgrade ICUor by using the GUI client Porticus This disappeared after the new icu was installed.
Incompatible or unstable software
Xerox FST tools
It seems (?) that Xerox also would like to have the latest ICU. Under Snow Leopard, Xerox had an UTF-8 problem:
a automaton:
a a
b b ?
á Segmentation fault
á automaton:
á á
b b
č Segmentation fault
Other software
- QuickSilver
- a lot of GNU and other open-source utilities available also through Fink and MacPorts are now outdated by the versions included in Snow Leopard, unless you have been constantly keeping them up-to-date. Consider deleting everything, and reinstall as needed. Especially when building HFST old versions of common tools will create trouble. Using the Snow Leopard versions should be just fine.